Moving from SQL, to NoSQL and here we are, NewSQL
Category: development
SQL is good, at least good enough for many cases where performance and scalability do not matter much. It has nearly all the things we need, although this is also why it cannot fulfill many developers’ requirements when it comes to actual deployment. Nowadays especially, applications are getting more and more data(big data trend) and should scale horizontally for more and easier access from around the world. Therefore, more and more people came to believe that it has become the elephant in the room and want to get rid of its disadvantages.
So here comes NoSQL. Starting from early 21st century, a group of developers came together and started to develop “non SQL” database for scalability. Early examples of NoSQL dropped support for ACID(atomicity, consistency, isolation, durability) and instead of tabular relations used in relational databases(tranditional SQL DBs like Oracle, MySQL, PostgreSQL), they used “key-value”, document or graph for data storage(schemeless design). The special storage format also enables the data to be more flexible. (Google’s BigTable, Amazon’s DynamoDB, Facebook’s Cassandra). And because data is flexible, powerful query language like SQL is not being used. Instead, only simple data access APIs are provided. Besides what is mentioned above, these early NoSQLs do not have strong consistency for replica of data–they are promising “eventual consistency”, meaning that at some undetermined future point of time, consistency will guaranteed.
However, the unstructured data is not a piece of good news for applications that have evolving data schemes and complex schemes could be hard to manage too. Besides, unpredictable outcome of updates due to weak consistence are driving developers crazy too. After realizing this, in the case of Google, they built Spanner to support semi-structured data and synchronous cross-data-center consistency. As a result of semi-structured data scheme, a special query language is also developed for query. And here we are already talking about NewSQL.
(After Spanner, Google’s new DB project F1 actually support full-featured SQL)
So what is NewSQL? According to Wikipedia:
NewSQL is a class of modern relational database management systems that seek to provide the same scalable performance of NoSQL systems for online transaction processing (OLTP) read-write workloads while still maintaining the ACID guarantees of a traditional database system.
As you can see from the definition, the new trend is to picking up the dropped features of SQL–ACID to ensure transaction management’s correctness and people are also paying attention to consistency among data replica. NoSQL is great when it comes scalability and speed but clearly we want to more predictable behaviors. As quoted from Google paper, it is better to have application developers worry about too many transactions hurting performance than worrying about getting serializability from application code level.
We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions.
Why old SQL DB servers’ performance is not good enough, even for OLTP(online transaction processing) for which it is designed for? See the bench marking result below:
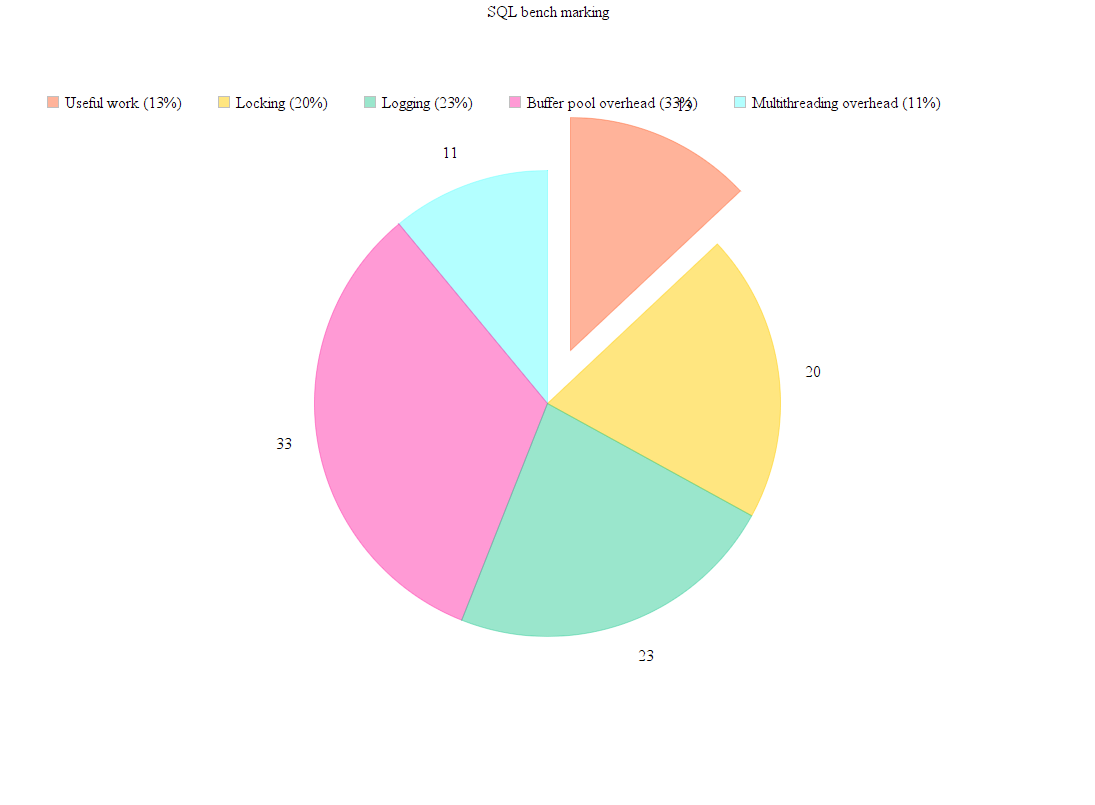
Of course there are other bench marking results online but basically this chart reflects different perspectives of bottle necks of old relational database: locking(for multiple concurrent transactions’ management), logging(for recovery), buffer pool(read db pages to memory and manage those pages), multi-threading overheads. These bottlenecks will be conquered in NewSQL with new implementations. What is more, NewSQL will take horizontal scalability into consideration from design level and try to provide a better, faster, more reliable solution for OLTP.
- buffer pool overheads: completely get rid of notion of buffer bool by using main memory only
- locking: multiversion(MVCC is proposed by Oracle for its own database concurrency control, with non-blocking read as huge advantage over locking based mechanism. the challenge for distributed database is to get the “true” time though)
- multi-threading: single-treaded(for multi-core architecture: have each stread running on each core but each thread is run separately on isolated memory space)
- logging: (solution for this to be researched and discussed later)built-in replica and fail-over; one-line fail-over or fail-back
For scalability, NewSQL inherits from NoSQL and with fault tolerance and consistency built-in. (For this part, I am not sure about the details inside, will add on to this later)
When NoSQL was becoming a big thing that everybody talks about, some believe that SQL is dead. However, it comes back to life in a newer form: NewSQL. In fact, as time passes, NoSQL is adding more and more features that were originally dropped from SQL.
Well, this whole blog is trying to introduce a new form of DB management. I am not here saying that old SQL is for sure dead or NoSQL will be replaced by NewSQL in the future. Situation varies and for example, a small web application that does not have a lot of data is good enough to go with MySQL; or some app requires a lot of data but it does not need strict integrity check and transaction management, developers can just go with NoSQLl; while when you need a very large-scale database management tool with SQL like integrity checking, transaction management and more predictable consistency, you can think of NewSQL.
References: