Using Tesseract to recognize datetime from pictures
Category: programming
Tesseract is a software for recognizing texts on images, or it is for optical character recognition. It was developed in HP and now maintained by Google. Currently it is not the most advanced and accurate character recognition program but it is open source and easy to use.
So there is one task, for which I got a lot of small images with datetime on each one. I need to recognize those datetimes. Those images are small but there is not much noise. After some Googling, I think I should try Tesseract, about which there are some examples and the documentation seems OK.
And the image is like:

Installing it seems trivial on Ubuntu as I think I will just go for 3.x instead of the latest version. After installing, I tested with one of the image (tesseract original_img.png out -psm 7), I got this output:
mam nmuzme
This is not even close in any sense!!! It cannot be this bad. So I searched a bit and somebody is saying that Tesseract does not handle small texts well. So I resized it:
img.resize((img.size[0] * 16, img.size[1] * 16), Image.ANTIALIAS)
The resized image (with adjustment to size for display):

8:00am 1 11301201 6
So if we ignore those two extra spaces in between, we can see that it is acceptable already–only takes ‘/’ as ‘1’. In fact, I guess by doing some simple post processing I am pretty confident that I will get good values already. But it is not good enough. Can I do better?
I can replace the yellow color to white, and increase contrast. Then it should be clearer to recoginize those characters I guess.
I got a clearer image, but result is still the same.
The further adjusted image (with adjustment to size for display):
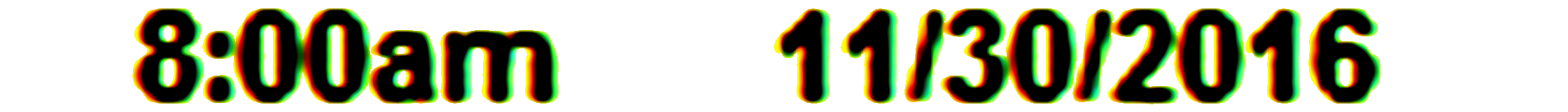
Does Tesseract support a set of candidate characters to recognize? Since in my use case, I only need to recognize a few digits and characters.
So now I have this as the tesseract additional configuration file:
tessedit_char_whitelist apm:0123456789/
And finally with tesseract /home/jgu/repos/dat_factset_terminal/new_img.png stdout -psm 7 tesseract.conf I got this:
8:00am 1 1130/2016
The Python code for processing the image is as follows:
"""recognize and extract datetime information from images
"""
import subprocess
from datetime import datetime
import numpy as np
from PIL import Image, ImageEnhance
class DTExtractor(object):
"""docstring for DTExtractor"""
def __init__(self, config):
super(DTExtractor, self).__init__()
self.img_out_path = config['img_out_path']
self.text_out_path = config['text_out_path']
self.conf_path = config['tesseract_conf_path']
def _process_img(self, img_path):
"""crop, resize, replace color, improve contrast
crop: remove leading noise part
resize: tesseract is not good with small fonts
replace color: replace yellow with white
improve contrast: make colors more distinct
"""
img = Image.open(img_path)
img = img.crop((3, 0, img.size[0], img.size[1]))
resized = img.resize(
(img.size[0] * 16, img.size[1] * 16), Image.ANTIALIAS
)
r1, g1, b1 = (200, 200, 100)
r2, g2, b2 = (255, 255, 255)
data = np.array(resized.convert('RGBA'))
red, green, blue, alpha = data.T
yellow_areas = (red > r1) & (green > g1) & (blue > b1)
data[..., :-1][yellow_areas.T] = (r2, g2, b2)
contrast = ImageEnhance.Contrast(Image.fromarray(data))
adjusted = contrast.enhance(3)
adjusted.save(self.img_out_path)
def extract_dt(self, img_path):
cmd = 'tesseract {} {} -psm 7 {}'.format(
self.img_out_path, self.text_out_path, self.conf_path
)
self._process_img(img_path)
proc = subprocess.Popen(cmd, stderr=subprocess.PIPE)
_, err_msg = proc.communicate()
if err_msg:
raise ValueError(err_msg)
with open(self.text_out_path, 'rb') as ifile:
content = ifile.read()
content = content.strip()
patterns = [
'%I:%M%p %m/%d/%Y', '%I:%M%p %m1%d1%Y',
'%I:%M%p %m/%d1%Y', '%I:%M%p %m1%d/%Y'
]
dt = None
for pattern in patterns:
try:
dt = datetime.strptime(content, pattern)
break
except ValueError:
continue
if dt is None:
raise ValueError('Could not recognize datetime in %s', img_path)
return dt